In the rapidly evolving landscape of education technology, few tools have generated as much discussion—and anxiety—as Turnitin’s AI writing detection capabilities. Since the integration of these features, institutions globally have adopted them in an effort to maintain academic integrity in the face of large language models (LLMs) like ChatGPT.
However, a critical question remains at the forefront for students, educators, and administrators alike: Is the Turnitin AI detector always accurate?
There is a common misconception that AI detection tools function as infallible “lie detectors,” providing definitive proof of whether a document was written by a human or a machine. This assumption is risky. Relying solely on an algorithmic percentage to make high-stakes decisions about academic dishonesty can lead to unfair outcomes.
It is vital to understand that Turnitin itself acknowledges the limitations of its technology. The company emphasizes that their AI detection scores should be treated as data points indicating potential AI use, not as absolute verdicts.
This article provides a comprehensive, research-based examination of Turnitin’s AI detection reliability. We will explore how the system works, why it explicitly hides scores below a certain threshold, the reality of false positives, and why human judgment remains irreplaceable in interpreting these reports.
How Turnitin’s AI Detector Works
To understand the accuracy of Turnitin’s AI detection, it is necessary to first understand its underlying mechanism. Unlike traditional plagiarism checkers that look for exact text matches across a database, AI detection works by analyzing linguistic patterns and probability.
Turnitin’s AI detector is trained on vast amounts of data, including both human-written academic papers and AI-generated text. The model analyzes a submitted document by breaking it down into segments—typically sentences or paragraphs. It then evaluates these segments based on characteristics inherent to how LLMs generate language.
LLMs are essentially next-word prediction engines. They select the most statistically probable next word in a sequence based on their training data. Consequently, AI-generated text often exhibits high levels of predictability and consistent sentence structures. Human writing, by contrast, tends to be more varying, sometimes unpredictable, and structurally diverse.
Turnitin’s detector measures features such as “perplexity” (how unpredictable a text is to the model) and “burstiness” (variations in sentence length and structure). If a document consistently uses highly probable word choices and uniform sentence structures across multiple segments, the detector assigns a higher probability that it was AI-generated.
It is crucial to note that the detector is estimating the likelihood that text patterns match those of an AI; it is not “identifying” the AI itself.
Recommended Reading: How AI Detectors Identify ChatGPT-Written Text.
What Does “Likely AI-Generated” Actually Mean?
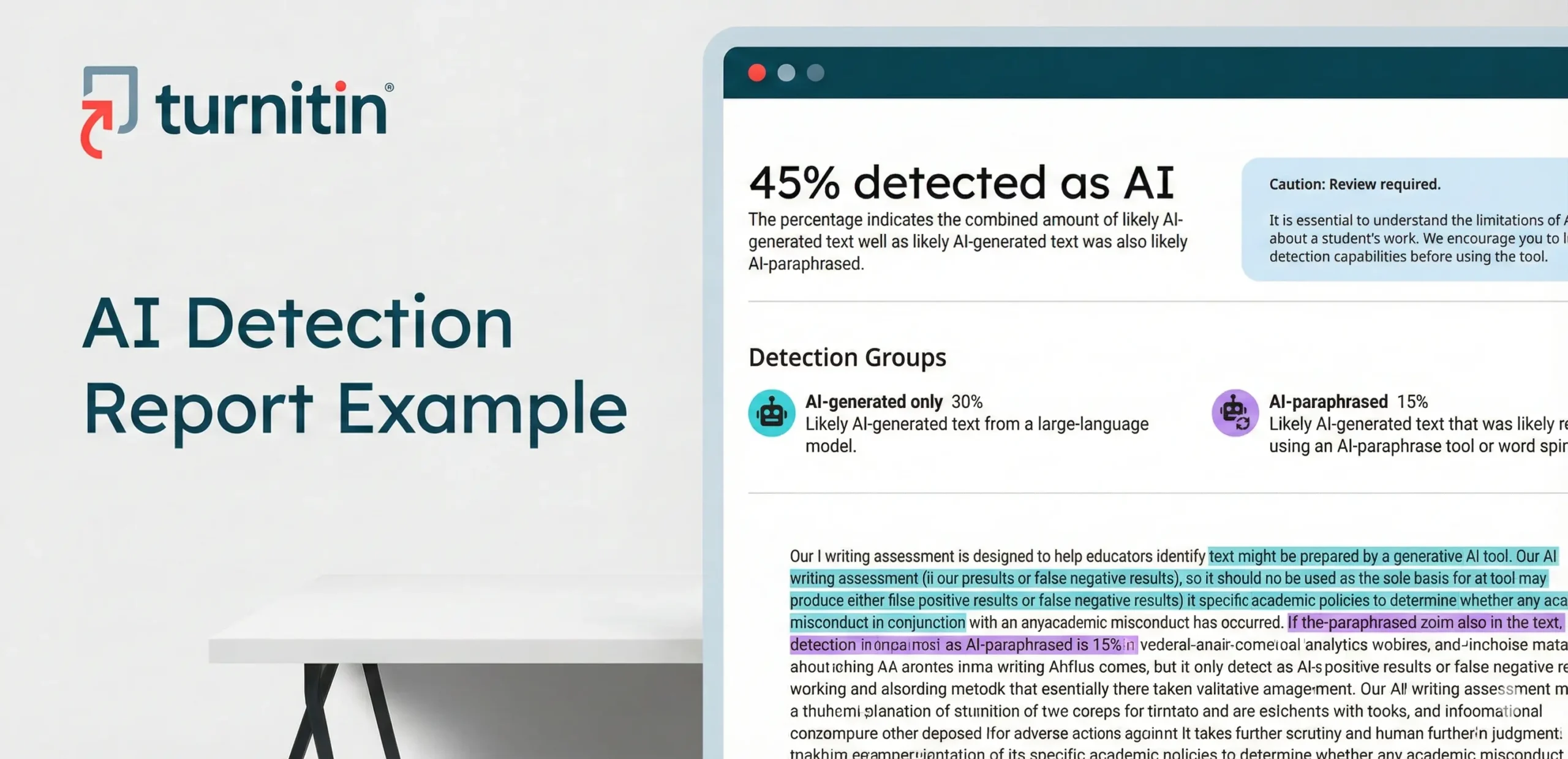
When a Turnitin report returns an overall percentage labeled “likely AI-generated,” it is often misinterpreted as a definitive binary conclusion—Human vs. AI. This is incorrect.
The overall score is an aggregate indicating the percentage of qualifying text segments in the document that the model determines—with a high degree of confidence—displays patterns typical of AI writing. For example, a 40% score does not mean the entire paper is “40% fake.” It means that roughly 40% of the analyzed sentences contained linguistic markers strongly correlated with AI generation.
Furthermore, modern writing practices complicate this detection. Many students now use AI tools for brainstorming, outlining, or drafting, followed by significant human editing. This results in “hybrid text.” AI detectors struggle with hybrid texts because human editing introduces the unpredictability that models usually associate with human authorship, potentially lowering the detection score even if AI was heavily involved in the process.
Therefore, “likely AI-generated” should be interpreted as a signal indicating that further scrutiny by a human instructor is warranted, rather than proof of academic misconduct.
Why Turnitin Hides AI Scores Below 20%
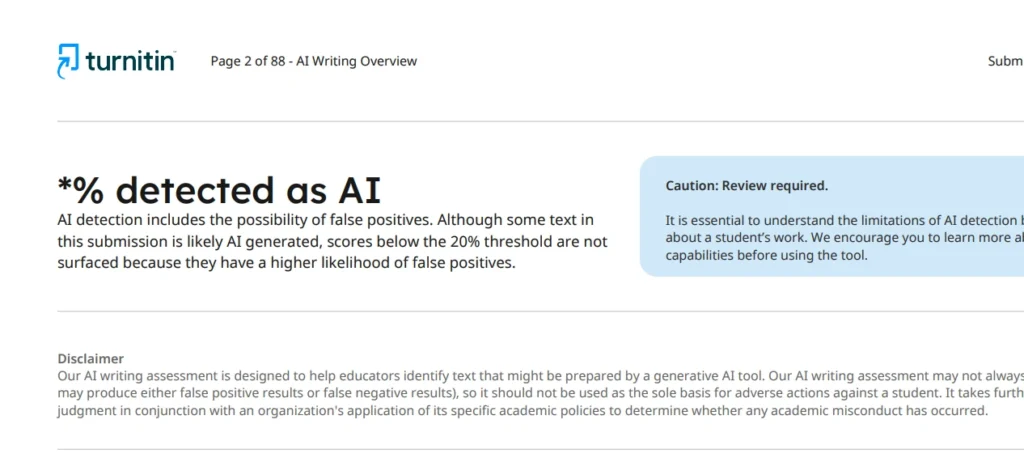
One of the most significant, yet often misunderstood, aspects of Turnitin’s AI detection reliability is its handling of low percentages. Turnitin has implemented a deliberate design choice: if the AI detection score is below 20% (1% – 19%), it is not displayed to the user. Instead, the report will typically show an asterisk (*%) indicating that the score is below the threshold required to be statistically meaningful.
Why does Turnitin do this? The answer lies in statistical reliability and risk reduction.
At lower percentages, the “noise” in the data increases. The likelihood that the flagged sentences are merely coincidental matches to AI patterns, rather than actual AI generation, becomes too high to be reliable. By suppressing scores below 20%, Turnitin aims to reduce the incidence of false accusations based on statistically insignificant data.
This threshold highlights that low-level flagging is considered normal and not necessarily indicative of cheating. Educators who are unaware of this mechanism might wrongly assume that a hidden score means a completely “clean” paper, or conversely, get suspicious about why a score isn’t showing. Understanding this 20% benchmark is essential for accurate interpretation.
Further Reading: Why Turnitin Doesn’t Show AI Scores Below 20% — What *% Means
Understanding False Positives in Turnitin AI Detection
The most critical limitation of any AI detection tool is the existence of false positives. A false positive occurs when text genuinely written by a human is incorrectly flagged by the detector as AI-generated.
Is Turnitin AI detector accurate enough to avoid these entirely? No. Turnitin has been transparent about this fact. Their documentation explicitly states that while they strive to maximize accuracy, there is a non-zero rate of false positives.
False positives can occur for several reasons. The primary cause is that some human writing styles naturally mimic the predictable, structured patterns that the detector associates with AI. The detector is looking for a correlation, not causality. If a student writes in a highly formulaic, repetitive, or overly generic manner, their work may trigger the algorithm solely based on linguistic probability, even if they never touched a generative AI tool.
Because of this inherent risk, Turnitin includes disclaimers urging educators to use their professional judgment and consider the student’s previous work, drafting history (if available in platforms like Google Docs), and in-class performance before making accusations based on the AI score.
Can Human-Written Text Be Flagged as AI?
Expanding on the concept of false positives, it is helpful to look at real-world scenarios where human-written text might be wrongly flagged. Research and anecdotal evidence suggest that certain groups of writers may be disproportionately affected by AI detection inaccuracies.
Non-Native English Speakers: Writers for whom English is a second language often rely on standard phrases, transitional words, and simpler sentence structures to ensure clarity. Unfortunately, these are often the same linguistic patterns that LLMs overutilize, leading to a higher likelihood of false flags for ESL students.
Rigid Academic Writing: Highly structured assignments, such as lab reports or technical papers that require very specific phrasing and minimal personal voice, can sometimes appear “robotic” to an AI detector.
Neurodivergent Writers: Some research suggests that neurodivergent individuals may employ writing patterns—such as high consistency or specific repetitive structures—that detectors misinterpret as algorithmic.
These scenarios underscore why an AI score should never be the sole determinant in an academic integrity case. A human instructor reviewing the flagged sections can often distinguish between the “stilted but human” writing of a struggling student and the syntactically perfect but shallow output of an AI.
Is Turnitin More Accurate Than Other AI Detectors?
Given the limitations, how does Turnitin compare to alternatives? Turnitin is generally considered one of the more reliable tools available to educational institutions, primarily due to its access to a massive, proprietary database of student writing. This allows them to train their models specifically on the type of content submitted in academic settings, rather than just generic web content.
Many free, public-facing AI detectors are trained on broader datasets and often yield higher rates of both false positives and false negatives.
However, institutional tools like Turnitin are typically tuned to be conservative. They prioritize lowering the false positive rate (avoiding wrongful accusations) over catching 100% of AI-generated text. This means they may miss some instances of AI use (false negatives) in order to ensure that the text they do flag is flagged with higher confidence.
Ultimately, no current tool provides 100% accuracy in AI detection.
Recommended Reading: Top 6 AI Detection Tools Compared: Which One Is Most Reliable?
Final Verdict — Is Turnitin AI Detector Always Accurate?
To answer the question directly: N0, the Turnitin AI detector is not always accurate.
It is a sophisticated, data-informed probabilistic tool designed to identify patterns typical of AI writing. It is not proof of authorship. While Turnitin has taken significant steps to ensure reliability—such as implementing the 20% threshold to reduce statistical noise and explicitly warning users about false positives—it is not infallible.
The misinterpretation of AI scores poses a greater risk to academic integrity than the AI tools themselves. When educators treat a probability score as absolute fact, students may be wrongfully accused, leading to damaged trust and severe academic consequences.
Therefore, Turnitin’s AI detection system should be regarded as one component in a broader assessment of a student’s work, always supplemented by human review, contextual understanding, and academic judgment.
Frequently Asked Questions (FAQs)
No. No AI detection tool currently available is 100% accurate. Turnitin determines the statistical probability that text matches AI patterns, which is not the same as definitive proof.
Yes. False positives, where human-written text is flagged as AI, do occur. This happens when a student’s natural writing style happens to mimic the predictable patterns of generative AI.
Turnitin includes disclaimers to ensure educators understand the tool’s limitations and do not rely solely on the score for disciplinary actions. They emphasize that human judgment is required to interpret the results.
Generally, no. Turnitin hides scores below 20% because they are statistically unreliable. Small percentages of flagged text can occur coincidentally in completely original human writing.
Universities should treat AI scores as indicators indicative of potential AI use, not as hard evidence of cheating. Scores should trigger a review process that includes looking at the student’s writing history and having a conversation with the student.
Was this helpful?